This chapter describes how to configure FlowTraq Server using the configuration file, which includes a number of advanced features capable of significantly affecting FlowTraq's performance and operation. Typically, this requires restarting the FlowTraq Server daemon, or signaling a 'soft' restart using the UNIX hangup signal.
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
Many of the options in this section have the ability to significantly harm performance, or put the FlowTraq service in an inoperable state. Please contact FlowTraq Support for assistance with these options. |
The procedure for starting and stopping FlowTraq Server depends on the host operating system.
On all versions of Windows, use the Services control panel.
Click Start, then Run, enter "services.msc" in the Run field, and click Run.
In the table that appears, find "ProQueSys FlowTraq Server".
Start or stop FlowTraq Server by right-clicking its entry in the table and selecting the appropriate menu item.
On Mac OS X, use launchctl. Open a Terminal window (from Applications->Utilities) and use the following commands to start and stop FlowTraq Server.
% sudo launchctl load / /Library/LaunchDaemons/com.proquesys.flowtraq.plist % sudo launchctl unload / /Library/LaunchDaemons/com.proquesys.flowtraq.plist
On Linux systems, use the launch script in /etc/init.d. Open a shell and use the following commands to start and stop FlowTraq Server. (For a note on Red Hat Linux, see below)
% sudo /etc/init.d/flowtraq start % sudo /etc/init.d/flowtraq stop
Some users have observed that Red Hat Linux does not always permit FlowTraq enough time to cleanly stop before issuing a SIGKILL, which can result in loss of data. To shut down FlowTraq cleanly in such a case, isse the FlowTraq process a SIGTERM signal instead.
% sudo killall -SIGTERM flowtraq
On BSD, use the launch script in /etc/rc.d. Open a shell and use the following commands to start and stop FlowTraq Server.
% sudo /etc/rc.d/flowtraq start % sudo /etc/rc.d/flowtraq stop
On Solaris, use svcadm. Open a shell and use the following commands to start and stop FlowTraq Server.
% sudo svcadm enable flowtraq % sudo svcadm disable flowtraq
Many of the configuration options do not require a full restart to reconfigure, and need only a signal to the FlowTraq Server daemon to notify it that new configuration parameters are available and should be read.
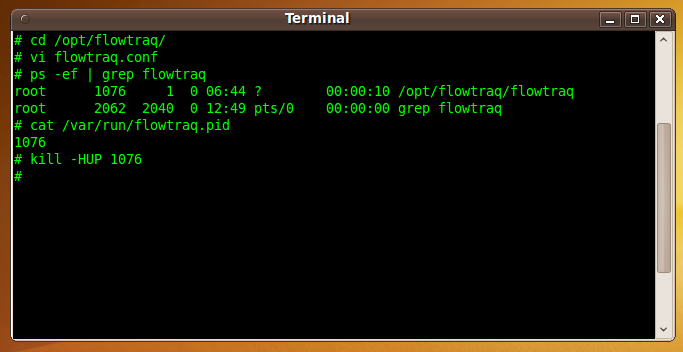
On non-Windows platforms, signal FlowTraq Server by sending the SIGHUP or "hang-up" signal to the flowtraq process. To do this, take the following steps:
Discover the process ID (PID) of the
flowtraqprocess by using thepscommand:% ps -ef | grep flowtraq
The PID will be among the output of the
pscommand.(Altenatively, you may read the contents of the PID file stored in /var/run/flowtraq.pid. Note that this technique works on all Unix platforms except Mac OS X. The
killallcommand may be used as well.)Use
killto send theSIGHUPsignal toflowtraq, using the PID you found in step 1:% kill -HUP XXXX
The process of backing up the FlowTraq database requires only making a copy of the files in it. This process may be followed to back up the FlowTraq Archive as well, as it uses the same format. It is not necessary to shut down FlowTraq Server in order to back up the session database.
To back up the session database, take the following steps:
Copy the full contents of the session database directory to the backup location.
![[Tip]](../common/images/admon/tip.png)
Session Database Location The default location of the session database depends on the host platform.
On Windows, it is
C:\Program Files\ProQueSys\FlowTraq Server\SESSIONDB.On Mac OS X, it is
/Library/Application Support/flowtraq/SESSIONDB.On Linux/Solaris/FreeBSD, it is
/opt/flowtraq/SESSIONDB.Note that if you edited FlowTraq Server's configuration file or selected a non-default installation directory or session database directory during installation, the session database may be located somewhere else. Check the Performance preference panel of FlowTraq Client.
Copy just the index again; that is, re-copy the
ns2xxxxx.metadbfile from the session database directory to the backup location.
Performing the backup in this way helps ensure that the indices are up-to-date. Although it is still theoretically possible to back up an out-of-date index with this technique, the alternative (having to shut the server down for the duration of the backup procedure) would result in significantly more data loss.
| Important |
|---|---|
If a serious gap in data is found after a recovery, take the following steps.
This will force a re-indexing of the existing data and ensuring data consistency. Note, however, that this operation takes time. |
To clear the FlowTraq session database, take the following steps:
Stop FlowTraq Server. (See Section 4.5.1, “Starting and Stopping FlowTraq Server” for more information on starting and stopping FlowTraq Server.)
Delete the contents of the session database directory. (Alternatively, move the contents to another folder).
Start FlowTraq Server.
Upon restart, the session database directory will be repopulated with files corresponding to an empty database.
FlowTraq Server keeps its main configuration parameters stored in a configuration file named flowtraq.conf. This file is located in FlowTraq Server's installation directory.
| Important |
|---|---|
FlowTraq Server may overwrite this file as a result of changes made from FlowTraq Client. |
The format of flowtraq.conf is plain text and is described below. You may edit it using your choice of text editor. However, in order for the changes to take effect, you must either restart FlowTraq Server (Windows) or signal it (all other operating systems). See Section 4.5.1, “Starting and Stopping FlowTraq Server” for more information on starting, stopping, and signaling FlowTraq Server.
The FlowTraq configuration file is organized in a key/value-pair hierarchy. In general, configuration keys can appear in any order in the file; however, some related keys must be placed together in sections, which are opened with <section-name> tags and closed by </section-name> tags.
Below is a typical flowtraq.conf.
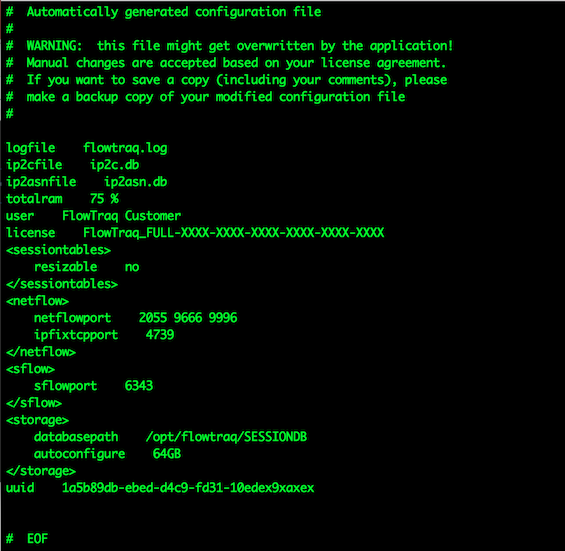
Notice the sections on <netflow>, <sflow>, <sessiontables>, <mail>, and <storage>. We will refer to keys in these sessions in their "path" notation: sflow/sflowport, indicating that they belong to a specific configuration section.
-
querythreads The number of threads the server keeps available to service queries and generate alerts and reports. If there are 4 pending queries, and 3 querythreads, one query will have to wait for a thread to become available before being serviced. Any value between 3 and 6 will usually suffice. We recommend using at least 2 querythreads. The maximum is 20. Each querythread will consume about 100MB of RAM.
numslicesFlowTraq will use 75% of the available CPU cores to handle queries by default. This means that on an 8-core system FlowTraq server will use 6 concurrent threads to process a single query. Note that the 'querythreads' parameter only specifies the number of concurrent queries that FlowTraq will handle. This means the 'querythreads' and 'numslices' values must be multiplied to obtain the total number of active threads processing user queries. This parameter can be set with either a percentage (eg. "100%") of available cores, or an absolute value (eg. "8").
-
ip2cfile This is the file that FlowTraq Server uses to resolve IP addresses to country codes. It is a compilation of the IP-to-country files provided by various Internet registries around the world. Each version of FlowTraq ships with an updated file. If you would like to receive updates to this file between FlowTraq releases, please contact FlowTraq support.
-
ip2asnfile This is the file that FlowTraq Server uses to resolve IP addresses to autonomous system number if that information is not provided as part of the flow record. It is derived from public WHOIS data, and each version of FlowTraq ships with an updated file. If you would like to receive updates to this file between FlowTraq releases, please contact FlowTraq support.
-
logfile This file records all errors, warnings, and status messages that are generated by the software. This file will grow over time, and is automatically rotated.
-
user The registered user name associated with the license key. License keys are issued in combination with a username, so it is important to copy your user name accurately.
-
license The license key that authorizes FlowTraq. License keys generally look similar to
FlowTraq_FULL-XXXX-XXXX-XXXX-XXXX-XXXX-XXXX.-
listenport By default, FlowTraq Server listens on port 9640 for client connections. If you change the listen port number to a privileged port (1024 and below), make sure that FlowTraq Server process runs with administrative privileges.
-
totalram FlowTraq allocates its RAM on startup in order to maximize efficiency and to ensure that it is able to allocate all the resources it needs. The totalram value tells FlowTraq how much RAM to allocate, and can be either a percentage of system RAM (e.g.
totalram 85%will allocate 85% of system RAM) or a set value (e.g.totalram 128GB). It is recommended to use a % value in most cases, unless resource contention with other processes (such as the OS, Apache, or ZFS) is causing performance issues.FlowTraq benefits from as much RAM as it can use. Any additional RAM allocated beyond that needed for its core functionality is used to augment the connection tracker table, memory cache, and disk buffers.
![[Caution]](../common/images/admon/caution.png)
Caution It is not possible to change
totalramoptions while FlowTraq Server is running. You must shut down FlowTraq Server before you can changetotalram.-
sessiontables/autoconfigure This value determines the amount of RAM that FlowTraq will attempt to allocate on startup for FlowTraq's main operation and session caching. The remainder is reserved for disk buffers. The value can be either a percentage (e.g.
autoconfigure 70%) or a set value (e.g.autoconfigure 1200MB). Thus, if system RAM is 10 GB, andtotalramis 80%, aautoconfigure 75%results in 6GB used for base functionality and session tables, and 2 GB for disk buffers.Important If
totalramis not set, thenautoconfigureis used in its place, and 10% is reserved for disk buffers.Caution It is not possible to change any of the
sessiontablesoptions while FlowTraq Server is running. You must shut down FlowTraq Server before you can change them.-
sessiontables/conntracksize(deprecated) This setting, in the absence of an
autoconfigurevalue, allows direct configuration of the size of the connection tracker in terms of the number of recods. In the vast majority of installs, this will not be used; setting this large enough that FlowTraq cannot allocate sufficient RAM will cause faulty operation.Each record occupies about 220 bytes of RAM. The value reflects the number of slots allocated, not the amount of memory occupied; multiply by 220 to get the resulting RAM size.
-
sessiontables/memcachesize(deprecated) This setting, in the absence of an
autoconfigurevalue, allows direct configuration of the size of the connection tracker in terms of the number of recods. In the vast majority of installs, this will not be used; setting this large enough that FlowTraq cannot allocate sufficient RAM will cause faulty operation.The value reflects the number of slots allocated, not the amount of memory occupied; multiply by 160 to get the resulting RAM size.
-
sessiontables/timeout By default, records that are in the active conntrack are moved to the memory cache after about 2 hours (7200 seconds). If you set this value to 0, then the records will stay in the connection tracker until it is full. At that point, the connection tracker will move the least recently updated sessions to the memory cache to make room for new incoming flows. Set any other value to change the default timeout. Value is in seconds. The default value is recommended.
-
sessiontables/toolong This value controls the breaking up of sessions that are very long-lived into chunks that get stored to disk separately. By default, if a session lasts longer than 8 hours (28800 seconds), then it is split up into multiple records. A flow lasting 24 hours would be stored in 3 session records of 8 hours each. If you don't like this behavior, set this value to 0 to disable it. Breaking very long session up into chunks yields a performance increase when queries are serviced from disk. It has no impact on memory based queries. The default value is recommended.
-
sessiontables/resizable The session tables consist of the connection tracking table and the memory cache. By default, these two tables can be resized by storing a different value for their keys to the main configuration file and sending a SIGHUP signal to the FlowTraq Server process. The ability to resize these tables adds flexibility to FlowTraq's configuration, especially if you are still tuning your parameters. However, this incurs a major performance penalty in the process of allocating memory at runtime, and it is highly recommended to not use resizeable sessiontables. To fix their sizes, set the value of this key to
no(default).-
netflow/netflowport Typical NetFlow/cFlow/jFlow/IPFIX/NSEL exporters records to UDP/2055, UDP/9666, and/or UDP/9996. FlowTraq Server opens these three ports for collecting incoming datagrams. Each port gets its own input buffer and processing thread. This means that powerful servers under heavy flow load can benefit from opening more ports and configuring exporters to send flows to the alternative ports. Doing this effectively spreads the load and prevents flow packets being dropped. In most scenarios this will be unnecessary. You may enter up to 8 space-separated ports in this list. These ports will handle NetFlow v1/v5/v7/v9, cFlow, jFlow, IPFIX, and NSEL.
-
netflow/ipfixtcpport IPFIX exporters can use TCP as the transport protocol. In this case the exporter connects to the FlowTraq server on the given TCP port to transport the IPFIX records. Similar to the UDP NetFlow configuration, opening multiple ports and distributing multiple exporters among them, will spread the CPU load over multiple threads, recuding congestion in busy networks.
-
netflow/ignoreoldnetflows Some NetFlow exporters suffer from heavy time skew. This often happens if the system clocks of the exporters are not properly set. FlowTraq Server attempts to correct for this. This can be done accurately because the exporters include their sense of the correct time in each NetFlow packet. If the clock of the exporters is set correctly, but the included flow records appear very old, FlowTraq tries to correctly fit them into the history. This may happen, for instance, if you are using old PCAP files as the input source of your flows. By default, this behavior is enabled. If you want to prevent FlowTraq from accepting "old" flow records, then set this value to
no.-
netflow/bufsize Systems with very heavy flow load, or with routers prone to send periodic spikes of flow updates instead of a constant stream, may need to increase the buffer size available to the NetFlow threads. Longer buffers give FlowTraq more time to process incoming flow records before new records are lost.
bufsizetakes a value of the form64Mfor 64 MB of buffer per thread.-
sflow/sflowport By default, FlowTraq Server listens on port UDP/6343 for incoming sFlow packets. Similarly to the
netflowport, you can enter multiple space-separated port numbers here to make FlowTraq Server listen on different or additional ports for sFlow datagrams. You may enter up to 4 ports in this list. These ports will handle sFlow v2/v4/v5.-
storage/autoconfigure The
storage/autoconfigurekey sets the size of the session database in MB, GB, or TB. For example,storage/autoconfigure 1200GBsets the session database to 1200 GB.-
storage/storageinterval FlowTraq Server continually tries to store new and updated records in the connection tracking table to the disk database. This is done in a round-robin style. After a pass through the connection tracker, the storage thread will take a brief pause of 5 seconds (by default). This allows systems with heavy I/O load to speed up queries that are serviced from the disk database. Systems under heavy flow load (over 20 million flows per hour) may benefit from setting this parameter to a value as low as 1, while systems with light flow load (up to 4 million flows per hour) can safely set this parameter to values as high as 60. Similarly, if you have very little RAM available, use a lower value, while if you have lots of RAM and a large
conntracksizevalue, you can gain disk I/O performance by setting this value higher. In most situations this value does not need tuning.-
storage/databasepath This is the location of the disk sessions database. FlowTraq Server will build a hierarchy of files in this directory as flows are received.
Caution It is not possible to change
storage/databasepathwhile FlowTraq Server is running. You must shut down FlowTraq Server before you can changestorage/databasepath.-
archive/autoconfigure The
archive/autoconfigurekey sets the size of the optional archive database in MB, GB, or TB. For example,archive/autoconfigure 1200GBsets the session database to 1200 GB.-
archive/databasepath This is the location of the archive database. FlowTraq Server will build a hierarchy of files in this directory as flows are received, just as with the main session database
Caution It is not possible to change
archive/databasepathwhile FlowTraq Server is running. You must shut down FlowTraq Server before you can changearchive/databasepath.-
userdata/userdatapath FlowTraq stores all user settings, reports, and workspace files in a separate directory. By default this directory is named
USERDATAand is created in FlowTraq Server's installation directory. By settinguserdatapath, the location of these files can be changed.Caution It is not possible to change
storage/userdatapathwhile FlowTraq Server is running. You must shut down the FlowTraq server before you can changestorage/userdatapath.-
userdata/maxsessionkeyage The commandline tools included with FlowTraq can establish a persistent session with the FlowTraq server based on pre-authenticated session keys. These keys can be generated with the '-us' option to any commandline tool, and subsequently used to re-authenticate from the same IP address for a short amount of time. The time-out of session keys can be configured with the 'userdata/maxsessionkeyage' in the server configuration file. The default timeout (in seconds) is 0, disabling the session key functionality. Set to a positive number to enable.
quickview/databasepathChange the default location of the NBI2 directory, which contains quickview histories, plugin configurations, and other information. Will grow by default up to 25GB.
quickview/1min/autoconfigureSet the maximum size for storing quickview history in 1 minute increments (default: 8G) This is the shortest-term quickview increment, and offers the finest-grained resolution, behind full-fidelity flow.
quickview/5min/autoconfigureSet the maximum size for storing quickview history in 5 minute increments (default: 8G)
quickview/1hr/autoconfigureSet the maximum size for storing quickview history in 1 hour increments (default: 8G) This is the longest-term quickview increment, and determines the length of the history available.
-
syslog/loghost When the
syslog/loghostis given a hostname or IP address, FlowTraq will send health requirements to the selected hosts via standard syslog. Events include logins (successful and unsuccessful), worker health (in cluster mode), and exporter health (including delays since last export of more than 2 minutes, and resumption of normal operation).![[Note]](../common/images/admon/note.png)
Note Syslog export in a cluster environment should in most cases only be configured on the portal node.
-
syslog/facility When the
syslog/loghostis configured, this option allows setting the syslog facility. Accepted values are LOCAL0 through LOCAL7.-
debuglevel This determines how verbose FlowTraq should be when writing to
logfile. In ascending order of verbosity, this key may be set to one of the following values: ALWAYS, CRITICAL, HIGH, MEDIUM, LOW. Be careful when using the more verbose settings such as LOW, as the log file may grow to be very large over time.-
maxclientlatency This is the number of seconds that FlowTraq will wait for a client to acknowledge a session download before disconnecting the client. Raw session record downloads (with the GUI, or 'ns2sq') can consume a large amount of network resources, causing other clients to slow down. If a client does not respond to the FlowTraq server in the specified amount of time, the raw session download is cancelled. The default value is 60 seconds. Lower values are recommended for busier system. Set to 0 to disable this feature.
In addition to the options presented above, FlowTraq can be configured to authenticate user logins using either TACACS+ or LDAP. These are detailed in the following sections. Further configuration options for clustered environments are also listed below.
FlowTraq supports external user authentication through the Terminal Access Controller Access-Control System Plus (TACACS+) Protocol. When users attempt to authenticate with a FlowTraq server, their credentials are first checked against the local FlowTraq user account database. If authentication fails, the specified TACACS+ server is be queried to authenticate the user.
If a user account authenticates for the first time through TACACS+, FlowTraq will treat that account as external, although local controls may still be applied. User settings such as dashboard layout and colorscheme will be stored on the FlowTraq server. It is also possible to apply user access controls to regular users, see Section 4.2.1.3, “User Filter Control”, or to make an external user an administrator.
A TACACS+ server is configured in the flowtraq.conf FlowTraq server daemon configuration file on the FlowTraq portal. After adding or removing a configuration, the FlowTraq daemon process must be restarted or sent a HUP signal to trigger a reconfiguration. Below is an example of a TACACS+ configuration:
<userdata> <tacacs> <srv0> server 192.168.2.70 port 49 secret MyPassw0rd </srv0> </tacacs> </userdata>
-
server The TACACS+ authentication server which FlowTraq should contact for user authentication.
-
port The TCP port on which FlowTraq should contact the specified TACACS+ service.
-
secret The shared secret you have configured on your TACACS+ system, to be used alongside user credentials.
| Important |
|---|---|
In most cases, cluster configuration is performed using the FlowTraq user interface. Manually changing cluster options may lead to poor performance. Due to the high potential to put the FlowTraq installation into an unusable state, please contact FlowTraq support for assistance with manual editing of any of the keys in the |
There are two portions to the cluster configuration: the portal side, and the worker size. A given FlowTraq install may both be a worker and have workers of its own. In the configuration file of any FlowTraq install with one or more workers, these keys dictate behavior:
-
recursion/workerX This key (subtituting a number between 0 and 127 for X, e.g.
recursion/worker7) takes as a value the IP address or hostname of a host (plus an optional TCP port; default is 9640) to query in response to a request for data. Whenever a session request or table request is received by this host, it contacts all of therecursion/workerXhosts, relays that query, and then waits for a response. When all responses have either returned or timed out, this FlowTraq host compiles the query result and either returns it to the user or (if it is acting as a worker) passes it up to the host that requested it.-
recursion/forwarderX This key (subtituting a number between 0 and 127 for X, e.g.
recursion/forwarder9) takes as a value the IP address or hostname of a host (plus an optional TCP port; default is 4739) to receive a share of the flow data received by this FlowTraq host in IPFIX format. The flows sent are determined by theforwardmodekey (below) and the number of forwarders configured. If a TCP connection cannot be opened, or closes, then this host will not receive a share of flows.-
recursion/forwardmode This key determines the way in which this FlowTraq host apportions shares of incoming flow data to send to the hosts listed as
forwardernodes. Ifrecursion/forwardmodeis set tobalance, then the incoming flows are divided (according to a hash of the flow characteristics) equally among all participating nodes. If it is set tomirror, then all hosts receive a full copy of the incoming flow stream.-
recursion/localmode This key determines the way in which this FlowTraq host handles incoming flow data. Accepted values are
keepandnokeep. In the former case, this FlowTraq hosts processes a share of the flows sent to it. For example, if threeforwardernodes are configured, andlocalmodeiskeep, the incoming flows will be divided into four portions, one of which will be stored by this FlowTraq node. If, by contrastlocalmodeisnokeep, the flows will be divided into three portions and this host will not store or process any.
FlowTraq supports external user authentication through the Lightweight Directory Access Protocol. This means that you can quickly grant user or administrative access to your FlowTraq server or cluster by mapping LDAP groups to FlowTraq roles. When users attempt to authenticate with a FlowTraq server, their credentials are first checked against the local FlowTraq user account database. If authentication fails, up to 4 LDAP servers can be queried to authenticate the user.
Using LDAP for authentication allows for a convenient way to manage access for many users at the same time from directory servers such as Active Directory. FlowTraq will treat these user accounts as external, although some local controls may still be applied. User settings such as dashboard layout and colorscheme will be stored on the FlowTraq server. It is also possible to apply user access controls to regular users, see Section 4.2.1.3, “User Filter Control”.
| Important Limitations of LDAP users |
|---|---|
Externally authenticating users comes with a couple of important limitations:
|
An LDAP server is configured in the flowtraq.conf FlowTraq server daemon configuration file. After adding or removing a configuration, the FlowTraq daemon process must be sent a HUP signal to trigger a reconfiguration. Below is an example of an LDAP configuration:
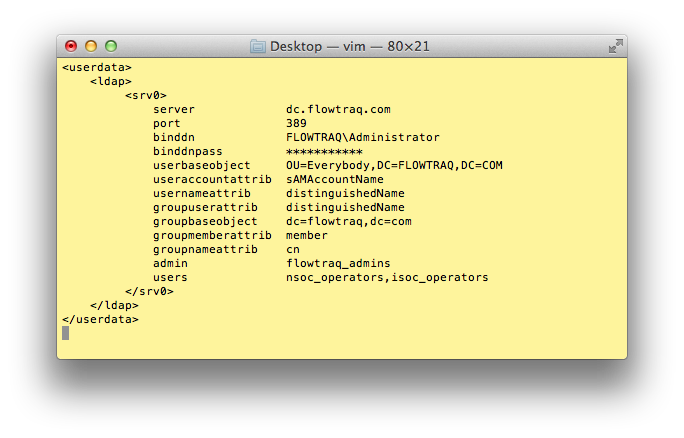
You may configure up to four LDAP server blocks srv0, srv1, srv2, and srv3, which will be searched in numerical order.
-
server The IP address or hostname of the LDAP server that FlowTraq should connect to.
-
port The TCP port of the LDAP service (389).
-
binddn The distinguished name of the LDAP account that is used to browse the directory service. This account must have sufficient privileges to query the LDAP server for users and groups. It is used to validate that users are valid members of the directory, and belong to groups that are mapped to FlowTraq users or administrators.
-
binddnpass The password for the LDAP account that is used to browse the directory service.
-
userbaseobject This is the base object that holds all the relevant user accounts in the directory. This object is searched for the credentials provided by the users to FlowTraq when they log in. Usually:
OU=Users,DC=FlowTraq,DC=com, or simplyDC=FlowTraq,DC=com.-
useraccountattrib The attribute of user objects that users will use to identify themselves to FlowTraq. You may pick any attribute that identifies a user in your directory. This is usually
sAMAccountName.-
usernameattrib This is the attribute of user objects that FlowTraq will search for and use to offer the credentials to the LDAP server for authentication. This is usually an attribute that uniquely identifies the user in the domain. A good value is
distinguishedName.-
groupuserattrib This is the attribute of user objects that is used in to identify membership in groups on your directory server. Often the
distinguishedNameof the user is used to identify them as members of a specific group.-
groupbaseobject This is the base object that holds all the relevant group accounts in the directory. This object is searched for the groups provided by the user and admin mappings given by the
adminandusersparameters, to establish if the user who is attempting to login is a member of an appropriate LDAP group. Usually:OU=Groups,DC=FlowTraq,DC=com, or simplyDC=FlowTraq,DC=com.-
groupmemberattrib This is the attribute of group objects that is used to list all the groups member users. Usually:
member.-
groupnameattrib This is the attribute of group objects that is used to identify them in the
adminandusersmappings. Usually:cn.-
admin List all the LDAP groups that should have administrative access to the FlowTraq daemon. You may list up to 8 groups.
-
users List all the LDAP groups that should have regular user access to the FlowTraq daemon. You may list up to 8 groups.
| Important |
|---|---|
Note that it is possible to configure the same LDAP server multiple times, but with a different group mapping in each configuration. |
Users who require SSL encrypted LDAP communication will need to set up an SSL tunnel. The simplest method for doing so is to use a free tool such as stunnel, as described in this section, in a client mode.
First, download and install stunnel on the host running FlowTraq.
Next, obtain a suitable PEM file for use with your LDAPS server, if needed, and copy it onto your FlowTraq host. Local port 389 is used to indicate that the local side of the connection is unencrypted, and must match the FlowTraq configuration. Create an stunnel.conf configuration file:
cert = MYPEMFILE.pem client = yes [ldap] accept=127.0.0.1:389 connect=MY_LDAPS_SERVER_IP:636
If your LDAPS server does not require a PEM file, or you're not sure, create the configuration file:
client = yes [ldap] accept=127.0.0.1:389 connect=MY_LDAPS_SERVER_IP:636
Start the tunnel, and configure FlowTraq to connect to 127.0.0.1. To ensure that stunnel starts by default, set in /etc/default/stunnel4:
ENABLED=1
The ftum command line tool offers a powerful method for retrieving and monitoring server statistics, through the use of the -info switch. Details for using this command to retrieve host status are described in the command line tools section of this manual